Downturn

Tianhe-2
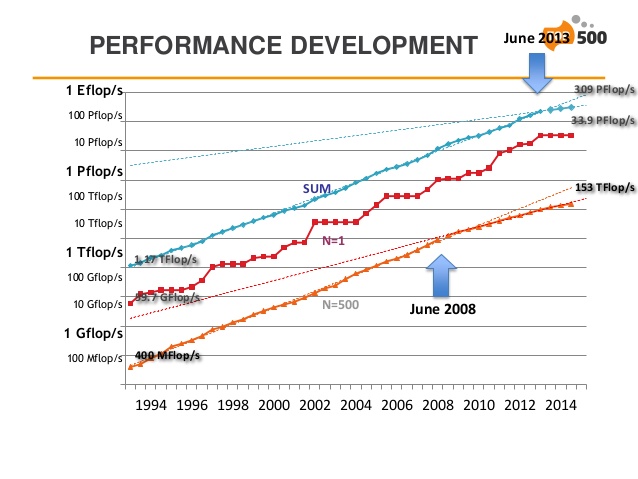
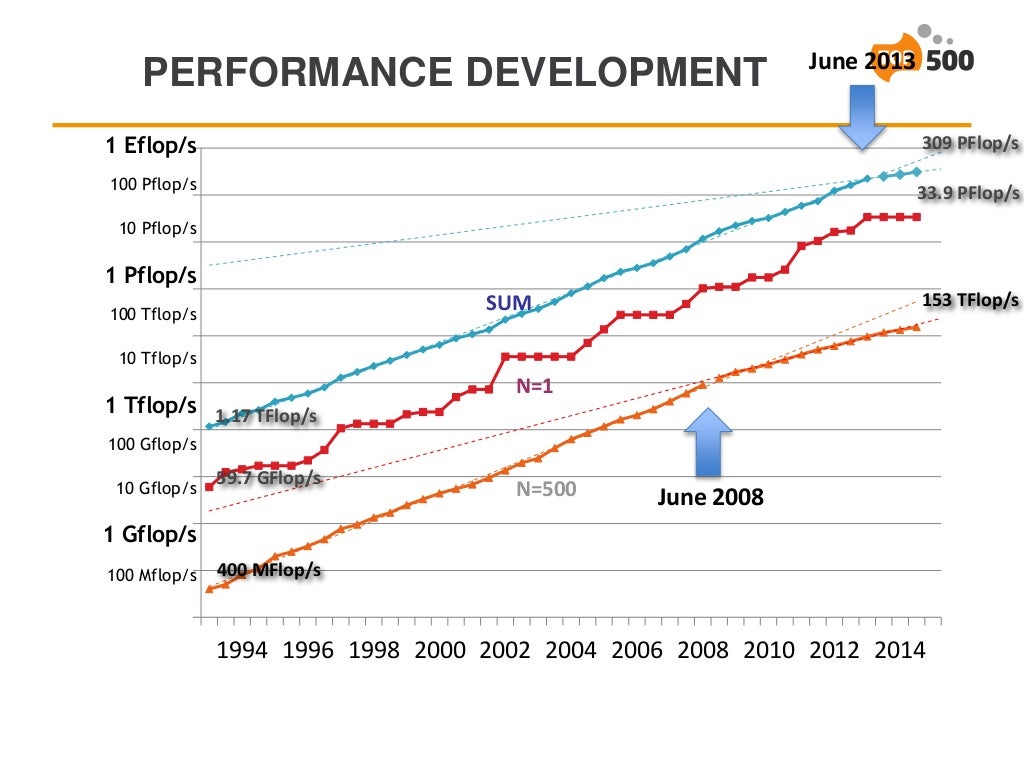
The semi-annual Top500 list shows a rather worrying trend for the 4th consecutive time in its last incarnation of Nov 2014. The list just hit its “lowest turnover rate in two decades.” The combined performance of the Top500 systems went from 274 Pflops to 309 Pflops in six months. The annual performance growth sits at ~23% at the moment, down from historic 90% per annum (measured between 1994-2008).
What this means is that there is practically no change in the Top500 most powerful computers in the world, and the trend is picking up speed in the wrong direction.
There are certainly cycles as technology and economies go through booms and busts, yet it seems there has never been this long a slowdown since 1993 when the list was first published.
There is only one new entry in the top-10 (in last place) with 3.58 Pflops from the US. To see the slope of the slowdown, here is a graph from the presentation.
There is reason to think the trend will reverse, eventually, but the best estimates point to the 2016-2018 period. That the trend can be traced to mid-2008 hints at the economic downturn as a cause. However, there is also reason to think competition has cooled off, or possibly technology is the bottleneck. This is support by the fact that a significant application area is government/military/classified, which aren’t nearly as sensitive to economic downturns as the scientific establishment. Technology is in the middle of a boom in terms of co-procs/embedded-proc as a new class of computers, so it’s hard to chalk this off as a technology bottleneck. If competition is to blame, it’s a mystery to me as to why this should be the case now, especially that US-China are more overtly in competition than ever before, at 46% and 12% entries respectively. Russia, with 2% of the Top500 entries, is at one of its lowest points in terms of relationship with Europe and the west since the cold war, and is implicated in a hot-war.
Supercomputing Performance Development and Stagnation
It should be mentioned that the US and Asia have lost a few percent points each in terms of entries since June last (Japan, the only exception, gained 2 entries) and Europe gained a few, surpassing China in raw power after being taken over two years ago. Perhaps the budgets and plans that reflect the political climate hasn’t yet materialized in terms of supercomputing power. It’s interesting to see how this will play out, as it’s a disturbing trend, one that has implications in terms of technology, science research, and a long history of healthy—and mischievous—competition between nations to simulate weather and destruction—both natural and man-made.
The presentation slides show the slowdown with all the glory and color of graphs and numbers.
Efficiency
The only relatively—good news is that the second most efficient system went from 3418 Mflops/Watt to a new record of 4272 Mflops/Watt since June last, improving on the top contender at 3459 Mflops/Watt by 23.5%.
In fact, there are five updated entries in the top-10 most efficient systems, four of which are new. Personally I find this exciting and encouraging, but without more raw power many applications can’t be improved further.
The Green500 list, which is similar to Top500 in that it tracks the world’s most power-efficient systems, as opposed to the most compute-capable ones, has more good news. The latest edition, which is published after Top500’s latest, lists two machines that are more power-efficient than the LX that holds the top entry in the Top500’s power-efficiency list. At 5271 Mflop/Watt, the L-CSC at the GSI Helmholtz Center in Germany improves on the LX by yet another 23.5%.

L-CSC at GSI
To put this in perspective, the most efficient consumer GPUs hit 23 Gflops (for AMD) and 28 Glops (for Nvidia). However, these are the numbers for single-precision (32-bit) floating-point ops, not the “full-precision” required by the Linpack, which requires 64-bits or more. The double-precision GPU performance is 1/4th the single-precision, at best. Typically it’s 1/8th or less. For AMD the most efficient double-precision GPU will reach 5.5 Gflops and 7.2 Gflops for Nvidia, which aren’t the most efficient single-precision GPUs (GPUs are differentiated for different markets, so they don’t compete with themselves). Meaning that even the most efficient consumer GPUs hardly makes the cut on their own, without any overhead or even a motherboard and CPU. The L-CSC uses Intel Ivy-Bridge CPUs and AMD FirePro Workstation GPUs to achieve the efficiency record.
Exa-FLOPS
The above record performance if scaled to 1 Exaflops would require a mere 190 MW energy. While this is still significant, it is the closest we’ve come to the DARPA target of 67 MW (by 2020).
Whether the architecture of the L-CSC scales to Exaflops or not is a different matter altogether, but the energy efficiency question which hitherto has been the most formidable obstacle to reaching Exa-scale performance seems to be well within reach. Still, 67 MW is a rather optimistic target as it would require a 2.8x efficiency improvement over the current numbers. Nonetheless, in 2007, when plans for Exa-scale supercomputing was laid out, the technology of the day would require 3000 MW when scaled to Exa-flops. There has been, in effect, a net 15x efficiency improvement in the past 7 years (no doubt in major part due to co-proc technology).
On a related note, at least the US seems to have plans to pushing the envelope towards Exa-scale computing, according to a very recent announcement. The US gov. plans “to spend $325m on two new supercomputers, and a further $100m on technology development, to put the USA back on the road to Exascale computing.” The $100m is especially exciting news as it’s not going to a vendor for building or upgrading a supercomputer, rather it’s allocated for technology. Beyond that, this should give a decent push for the healthy competitive spirit to start rolling again.
How to Use a Million Cores?
There has been a significant research and interest in parallel algorithms and libraries in the past decade—in major part—precisely to address the issue of scalability. Most implementation of algorithms do not scale to tens or hundreds of cores (let alone thousands or millions,) even if in theory the algorithm itself is reasonably easy to parallelize. The world’s fastest single machine (by a margin of 2x from the next competitor,) the Chinese Tianhe-2, a.k.a. Milkyway-2, has 3.12 million cores to play with.
The main issue has to do with communication. But in the parallelizing algorithms, the major problem is even closer to raw computing—overheads. It seems that the biggest bottleneck to parallelizing efficiently on even the same socket is the overhead of partitioning, scatter, and gather. The last step of which typically is the killer.(Interesting presentation on scalability with HPX and more published papers here.) I’ve been following some of the libraries and compilers in the C++ world and HPX as well as TBB seem to be doing a very decent and promising job. HPX is especially promising and is well worth taking a look into as it’s C++ standards conformant and even has a good chance of getting some of its functionality into the standards body by 2017 (the next planned C++ standard voting meeting). In addition, it supports distributing across compute nodes. Like TBB, it’s OSS.
But the shorter answer is that these machines are designed for specific applications and typically have the software available, so there is a very good idea as to what hardware characteristics will deliver the best performance, both computational and power consumption. In addition, they run multiple parallel versions, or scenarios, concurrently that are independent of one another, which reduces scalability issues dramatically. This is actually a good thing for simulations as some, if not most, scenarios are discarded anyway, and the sooner one discovers their unfitness the better. I do not have the reference at hand at the moment, unfortunately, but I believe the record for scaling on the most cores was reached sometime back (circa 2013) with 1 million cores utilized towards solving a single problem, which is impressive by any measure.
Often the supercomputer is shared between users. The US Titan, the second fastest machine, has thousands of users and applications running on it. To that end the Lustre filesystem (based on ZFS) was practically created for it. With 40 PB storage and 1.4 TB/s throughput _on disk_, it’s not exactly a standard-issue I/O system. (This presentation on Lustre shows the performance achieved on Titan.) This means that Linpack numbers should be taken with a large grain of salt when comparing these behemoths.
Why Supercompute?
I’m perhaps as cynical as anyone about the utility of these beasts of a machine and I’ve pointed out the military use of these machines, which is unfortunate. However, I much rather have the testing of nuclear (and other WMD) done in virtual simulations on machines that push the state of the art and most likely trickle the technology down to civilian and commercial use, than to have them done by actually blowing up parts of our planet. Indeed, it was precisely the ban on nuclear arms testing that first pushed the tests literally underground (the French and the US are the best known examples of covertly resuming tests underground and in the oceans,) before ultimately going fully into simulation. As such, I’m not at all torn on my position when it comes to the use of supercomputers for military purposes, considering the aggressive nature of homo-sapiens (irony noted in the lack of wisdom when playing with WMDs) and the fact that there is beneficial side-effects to this alternative.
Now, if only we could run conflicts through simulations to avoid the shedding of blood, much like how territorial animals display their prowess by war screams and showing their fangs to avoid physical conflict, and walk away when the winner is obvious to both, I think the world would be a vastly better place. Alas, something tells me we do like getting physical for its own sake, often when there is absolutely nothing of significance to gain, and much too much to lose. Nobody said pride was a virtue without a cost.
")
{kind=link}